Embodied Question Answering (EQA) requires an agent to interpret language, perceive its environment, and navigate within 3D scenes to produce responses.
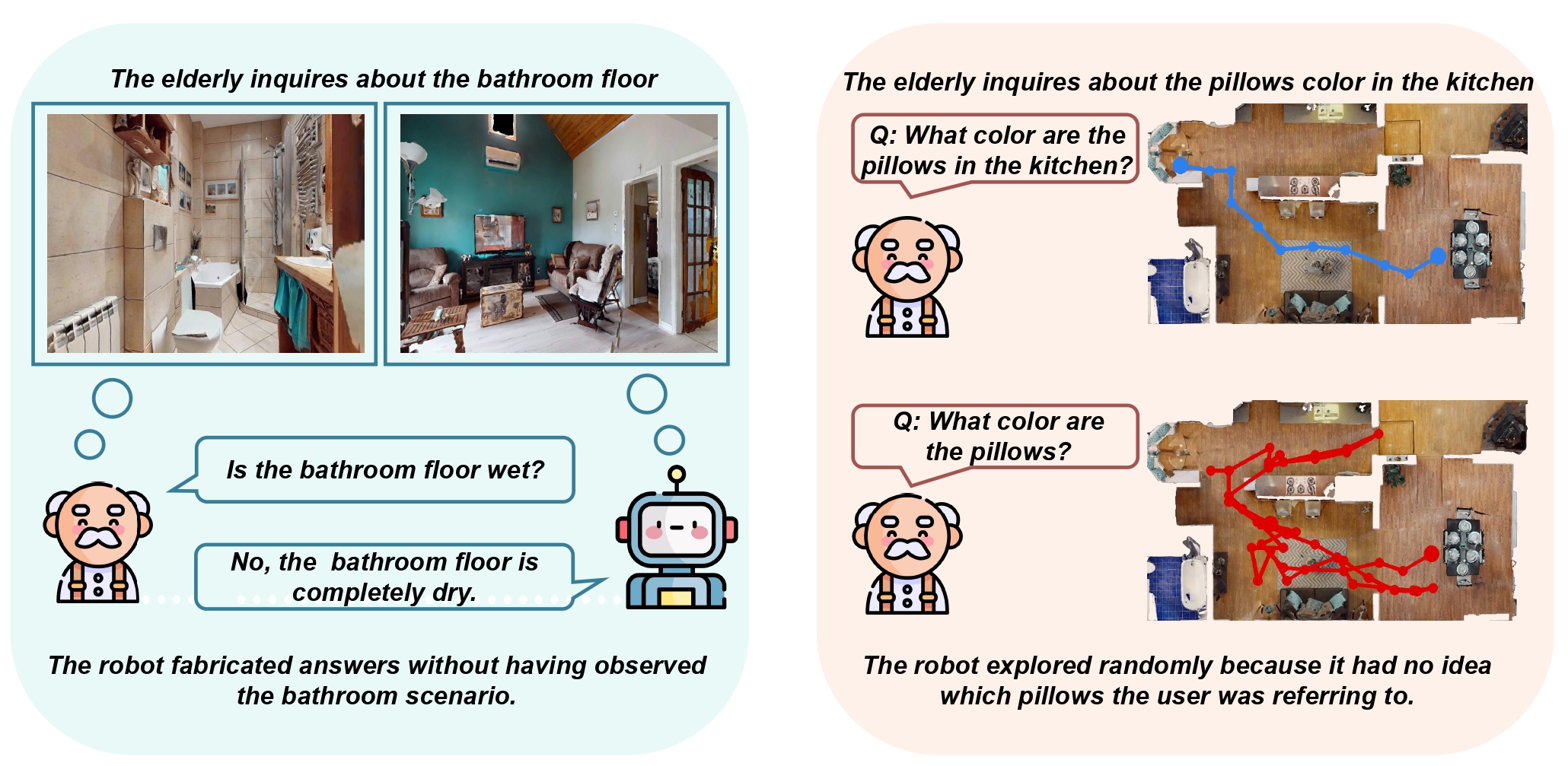
Existing EQA benchmarks assume that every question must be answered, but embodied agents should know when they do not have sufficient information to answer.
In this work, we focus on a minimal requirement for EQA agents, abstention: knowing when to withhold an answer.
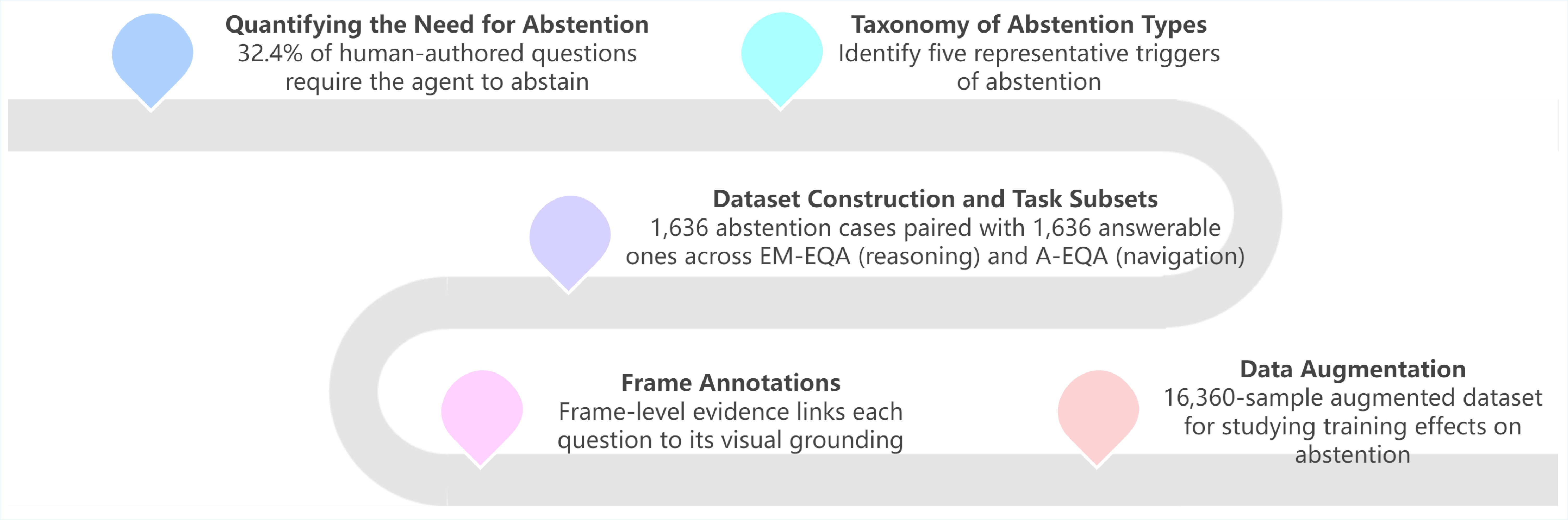
From an initial study of 500 human queries, we find that 32.4% contain missing or underspecified context.
Drawing on this initial study and cognitive theories of human communication errors, we derive five representative categories requiring abstention: actionability limitation, referential underspecification, preference dependence, information unavailability, and false presupposition.
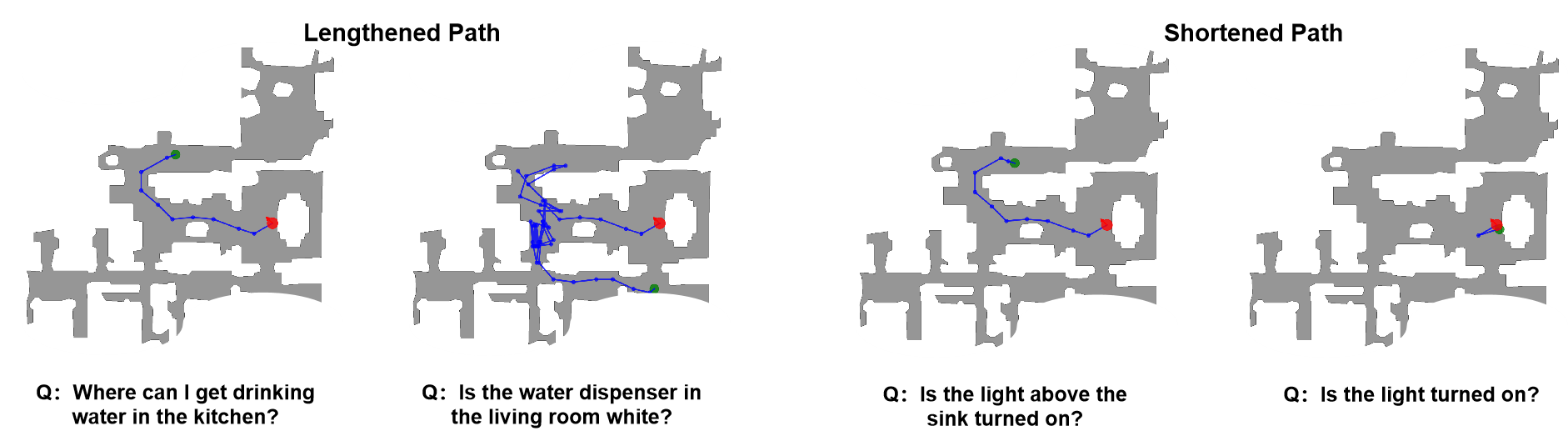
We augment OpenEQA by having annotators transform well-posed questions into ambiguous variants outlined by these categories.
The resulting dataset, AbstainEQA, comprises 1,636 annotated abstention cases paired with 1,636 original OpenEQA instances for balanced evaluation.
Evaluating on AbstainEQA, we find that even the best frontier model only attains 42.79% abstention recall, while humans achieve 91.17%.
We also find that scaling, prompting, and reasoning only yield marginal gains, and that fine-tuned models overfit to textual cues.
Together, these results position abstention as a fundamental prerequisite for reliable interaction in embodied settings and as a necessary basis for effective clarification.